Руководство по графическому процессору для вывода LLM

Несколько дней назад мы обсуждали стратегию использования графических процессоров для ИИ в OVHcloud. После нескольких часов звонков я понял, что нашим финансовым коллегам всё ещё сложно разобраться в технических аспектах этой темы, поэтому я решил написать для них руководство. Потом кто-то пошутил, что многие наши клиенты тоже были в замешательстве, поэтому руководство теперь оформлено в виде поста в блоге.
Это руководство посвящено графическому процессору для вывода больших языковых моделей (LLM). Под «производительностью» мы подразумеваем количество токенов в секунду. Это руководство не претендует на техническое погружение, но оно поможет вам выбрать правильную конфигурацию графического процессора для вашего сценария использования. Многие детали были упрощены для удобства и доступности информации.
TL:DR – Лучшие варианты вывода LLM в OVHcloud (по состоянию на июль 2025)
Это лучшие варианты развертывания, доступные на данный момент в OVHcloud для LLM-инференса. Предложение будет развиваться по мере выпуска новых графических процессоров.

1 — Определите область своих требований
Прежде чем двигаться дальше, попробуйте определить свои требования (ответы на следующие вопросы помогут вам выбрать наилучшее решение).
- Какую модель вы хотите развернуть? (Например, Llama3 70B)
- Сколько у него параметров? (например, 7B, 70B, 120B)
- Какая длина контекста вам нужна? (например, 32 КБ, 128 КБ)
- Какой уровень точности или квантования? (FP16, FP8 и т. д.)
- Сколько пользователей одновременно? (Один пользователь? 10? 500? 10000 ?)
- Какой сервер вывода? (например, LLM, TensorRT, Ollama…)
- Необходимая пропускная способность? (например, задержка на пользователя, общее количество транзакций в секунду)
- Использование стабильное или нестабильное? Предсказуемое или нет?
2 – Выбор модели графического процессора – Дискриминантный критерий
а) Поддержка квантования/точности
Что такое квантование? Идея заключается в снижении точности весовых коэффициентов модели для уменьшения объёма памяти и вычислительных затрат ценой небольшого снижения качества модели. Квантование снижает затраты памяти и вычислительных затрат за счёт снижения точности (например, FP16 → FP8 → FP4), как правило, в ущерб качеству модели. Это компромисс.
В настоящее время модели LLM чаще всего публикуются в FP16, но часто развертываются в FP8, поскольку выигрыш в скорости значительно перевешивает потерю качества.
Поддержка квантования GPU
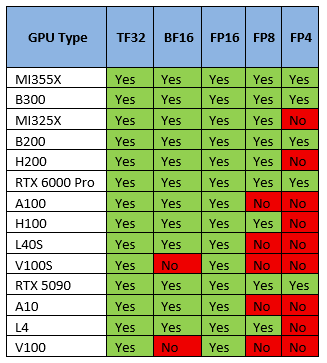
Большинство графических процессоров поддерживают не все типы точности/квантования, поэтому это дискриминантный критерий. Выберите графический процессор, поддерживающий нужный вам формат квантования.
б) Минимальное количество графических процессоров для запуска вашей модели
Для вывода необходимо загрузить все веса модели (**) в память (память видеокарты, а не ОЗУ) и оставить место для контекста/кэша. Либо памяти достаточно, либо это просто не сработает.
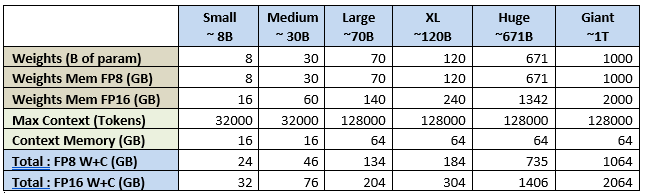
Вот практическое правило расчета необходимого объема памяти GPU для LLM:
Total GPU memory = (Parameters × Precision Factor) + (Context Size × 0.0005)

Пример: Llama 3.3 70B с контекстом 128 КБ в FP8 потребует 70 ГБ для весов модели + 62,5 ГБ для контекста.
Если мы применим эту формулу к нескольким стандартным размерам/контекстам LLM, то получим следующее:
Теперь применим это к самому распространенному графическому процессору, который вы сможете найти, чтобы получить минимально необходимое вам количество графических процессоров:
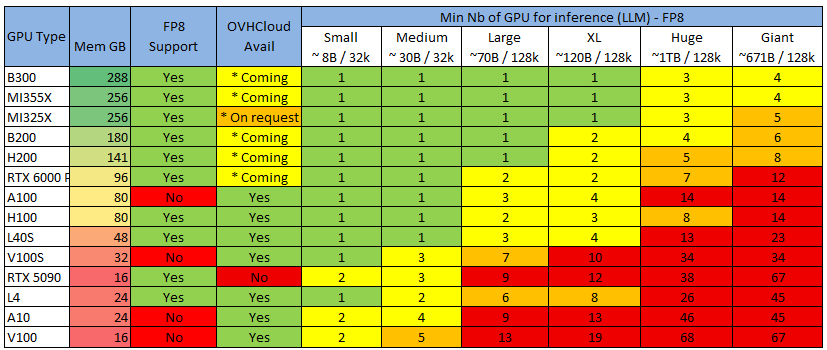

Color Legend, учитывая, что серверы обычно поставляются с 4 или 8 GPU (скоро 16 GPU)
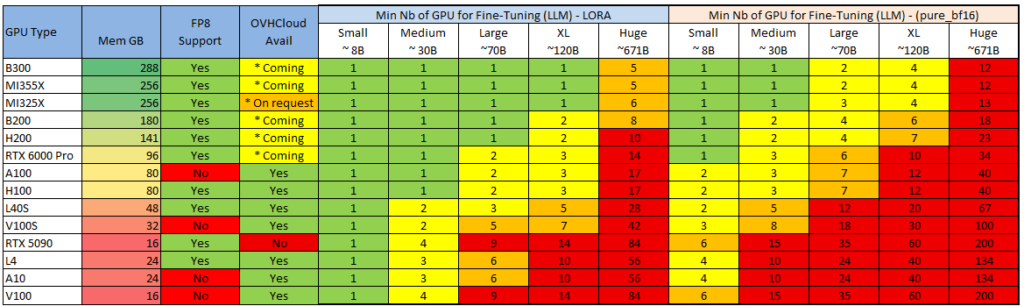
См. также 2 распространенных метода точной настройки:
Примечание: возможно запустить (небольшой) вывод LLM на ЦП (см. Llama.cpp ), но только для небольших моделей (или высоких уровней квантования с более низким качеством).
Примечание: можно сократить потребность в памяти, «выгрузив» часть слоев модели из ОЗУ, но я не буду об этом рассказывать (посмотрите Reddit-подписку LocalLlama — некоторые делают из этого вид спорта), так как производительность низкая, и я думаю, что если вы переходите в облако, то это ради реальных впечатлений
c) Совместимость с оборудованием
Последним критерием выбора графического процессора является аппаратная совместимость с некоторыми функциями серверов вывода.
Серверы вывода (программное обеспечение, на котором работает модель) могут иметь функции, несовместимые с определенными графическими процессорами (марки или поколения).
Они часто меняются, поэтому я не буду их перечислять, но вот пример для VLLM: docs.vllm.ai/en/latest/features/compatibility_matrix.html#feature-x-hardware_1
Самый распространенный пример, который мы видим, — это то, что механизм «Flash Attention» не поддерживается на видеокартах Nvidia поколения Tesla, таких как V100 и V100S
3 – Выбор конфигурации и развертывания графического процессора – Критерий производительности
а) Что влияет на производительность вывода?
Обзор
На общую производительность (т. е. количество токенов в секунду) влияют несколько элементов, приблизительный порядок важности которых следующий:
- 1 – Производительность графического процессора
- 2 – Производительность сети (между графическими процессорами и между серверами)
- 3 – Программное обеспечение (сервер вывода, драйверы, ОС)
Ниже приведено описание каждого из вариантов и варианты, которые можно выбрать.
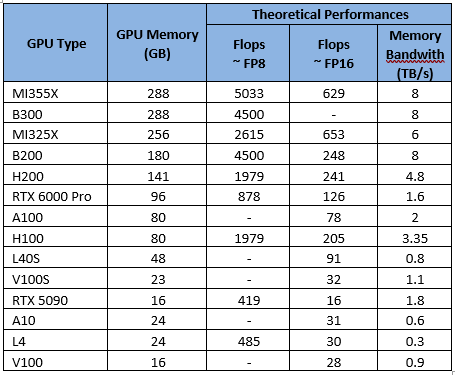
Производительность графического процессора
В основном это связано с вычислительной мощностью («флопсами») графического процессора и пропускной способностью его памяти (в зависимости от поколения).
Ознакомьтесь с теоретическими характеристиками (заявленными Nvidia и AMD), перечисленными ниже:
Производительность сети
При выполнении вывода ваши данные распространяются несколькими способами:
- Видеокарта — материнская плата: скорость зависит от типа и версии подключения. Обычно это PCIE или SXM (фирменное подключение Nvidia).
- Видеокарта-видеокарта: связь осуществляется либо через материнскую плату (PCIE/SXM), либо через прямое соединение с видеокартой. Nvlink — это решение от Nvidia.
- Сеть между серверами (при использовании нескольких серверов): Ethernet, Infiniband
Производительность программного обеспечения (сервер вывода, драйверы)
Производительность будет значительно варьироваться в зависимости от сервера вывода (VLLM, Ollama, TensorRT…), используемых базовых библиотек (Pytorch…) и базовых драйверов (Cuda, RocM).
В двух словах: используйте последние версии!
Не все серверы вывода обеспечивают одинаковую производительность и одинаковый набор функций. Я не буду вдаваться в подробности, но вот несколько советов:
- Ollama: Простота настройки и использования. Лучший вариант для одного пользователя.
- VLLM: Лучше всего подходит для быстрого получения последних моделей и функций, но сложно настроить.
- TensorRT: Лучшая пропускная способность, но есть задержка в поддержке новых моделей/функций и работает только на графических процессорах Nvidia.
а) Различные варианты развертывания
Теперь, когда вы знаете, какой графический процессор и сервер выбрать, у вас также есть несколько вариантов настройки архитектуры.
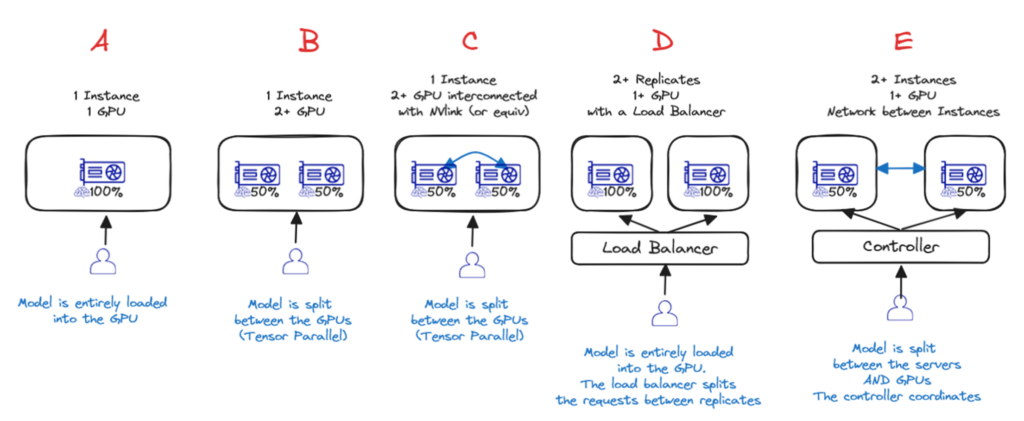
Вариант A — Один графический процессор
Если модель достаточно мала, чтобы поместиться в один графический процессор, то это лучший вариант!
Вариант B и C — один экземпляр, несколько графических процессоров (с межсоединени ем или без него)
Если для одного GPU это слишком много, то лучшим вариантом будет один сервер с несколькими GPU. Либо с Nvlink ( вариант C ), либо без него ( вариант B ). В этих двух случаях веса моделей распределяются по разным GPU, но за это приходится платить: производительность не будет в два раза выше, чем у одного GPU!
Вариант D — один экземпляр, несколько реплик с балансировкой нагрузки
Если модель помещается на 1 сервере (1+ GPU), но производительности недостаточно или вам необходимо динамическое масштабирование в зависимости от текущих потребностей, то лучшим вариантом будет использование нескольких реплик и добавление балансировщика нагрузки ( вариант D ) — это то, что AI Deploy предоставляет по умолчанию.
Вариант E — Распределенный вывод по нескольким серверам
Если модель слишком велика для размещения на одном сервере, необходимо распределить вывод по нескольким серверам ( вариант E ). Это самый сложный вариант (необходимо настроить сеть и программное обеспечение для кластеризации) и приводит к наибольшей потере производительности (из-за узких мест в межсерверной сети, а также из-за взаимодействия графических процессоров).
в) Какой продукт OVHcloud использовать?
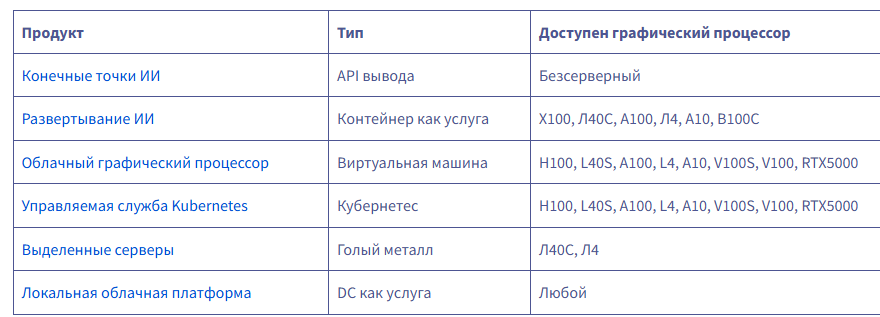
Для вывода у вас сегодня есть шесть вариантов на выбор:
endpoints.ai.cloud.ovh.net/
www.ovhcloud.com/en/public-cloud/ai-deploy/
www.ovhcloud.com/en-ie/public-cloud/compute/
www.ovhcloud.com/en/public-cloud/kubernetes/
www.ovhcloud.com/en-ie/bare-metal/prices/
www.ovhcloud.com/en/dc-as-a-service/
Если вам нужен полностью управляемый вывод, то AI Endpoints — определённо лучший вариант: это бессерверный сервис, где вы платите за количество использованных токенов. Вам не нужно развертывать модель или управлять ею.
Важно отметить, что вам нужно выбрать одну из предлагаемых нами моделей (вы не можете добавить свою). Тем не менее, мы приглашаем вас запрашивать новые модели на нашем Discord!
discord.com/invite/ovhcloud
AI Deploy — это продукт, специально разработанный для запуска серверов вывода, обладающий несколькими ключевыми функциями:
- Это контейнер как услуга: вы привозите свой собственный контейнер, мы им управляем.
- Простая конфигурация: вы можете запускать контейнер несколько раз с помощью одной командной строки и изменять параметры непосредственно через эту командную строку.
- Масштабируемость заложена в конструкцию: в любой момент вы можете добавить реплики, и мы управимся балансировкой нагрузки.
- Автомасштабирование: вы можете настроить автомасштабирование на основе пороговых значений ЦП/ОЗУ, а вскоре вы также сможете использовать пользовательские метрики (например, задержку вывода).
- Масштабирование до 0: Скоро вы сможете масштабироваться до 0. Если в течение некоторого времени на ваш сервер не отправляется ни одного запроса, мы останавливаем машину.
- Оплата поминутно, без обязательств.